

How Chat Infrastructure Can Serve 20,000 Concurrent Users on a Single Server While Cutting Costs
The architecture decisions and financial impact of building truly scalable conversational AI infrastructure
When your CFO reviews quarterly cloud spend and asks why conversational AI infrastructure costs have tripled while user engagement has only doubled, you need more than "the system is working well" as an explanation. Traditional chatbot infrastructure costs scale exponentially with usage, turning successful digital transformation initiatives into budget disasters.
Janan Tech advocates for efficiency-first architecture, whether deploying to the cloud or following our No-Cloud Ops philosophy. Most conversational AI platforms promise scale but deliver complexity. Traditional frameworks require constellations of services: Redis for sessions, separate action servers, message queues, extensive monitoring. The result? Infrastructure that's expensive, slow to start, and nightmarish to debug under load—whether in the cloud or on-premises.
What if there was a better way?
The Single Server Achievement: 20,000 Concurrent Users
Janan Tech set out with an ambitious goal: create conversational AI infrastructure that could handle massive concurrent traffic without typical overhead. The results exceeded expectations.
Here's what happened when Flowent was load-tested with 20,000 concurrent chat sessions sending frequent messages in a very short period:
| Performance Metric | Flowent Result |
|---|---|
| Cold start time per process | 830ms |
| Memory usage (baseline) | 12MB |
| vCPU usage (baseline) | 0% |
| Memory for 20k concurrent chat sessions | 12.39GB |
| vCPU usage for 20k concurrent chat sessions | 44% (355% on 8vCPU) |
| Average response latency | 1.51s |
| Servers required for 20k users | 1 VPS |
Yes, one server served 20,000 concurrent users with frequent message bursts while maintaining sub-2-second response times. For normal traffic patterns with typical user interaction rates, the same infrastructure can efficiently serve millions of concurrent chat sessions with just one or two instances.
The Architecture That Makes It Possible
1. Lightweight by Design
Flowent's architecture is fundamentally lightweight. Conversation state is efficiently managed through PostgreSQL, eliminating Redis caches or in-memory session stores. This design choice has profound implications:
- Massive vertical scaling – single servers can handle millions of users
- Zero warm-up time – no session data to sync or caches to populate
- Simplified deployment – no need for complex multi-instance orchestration
- Cost efficiency – no additional caching infrastructure required
2. Go's Concurrency vs Python's Limitations
Built in Go, Flowent leverages goroutines to handle thousands of concurrent connections with minimal memory overhead. Traditional Python-based frameworks are constrained by the Global Interpreter Lock (GIL), forcing heavy multi-process architectures.
The Concurrency Performance Gap:
By choosing Goroutines over traditional threads, you can avoid memory overhead, costly context switching, and inefficient task management. Here's what this means for enterprise decision-makers:
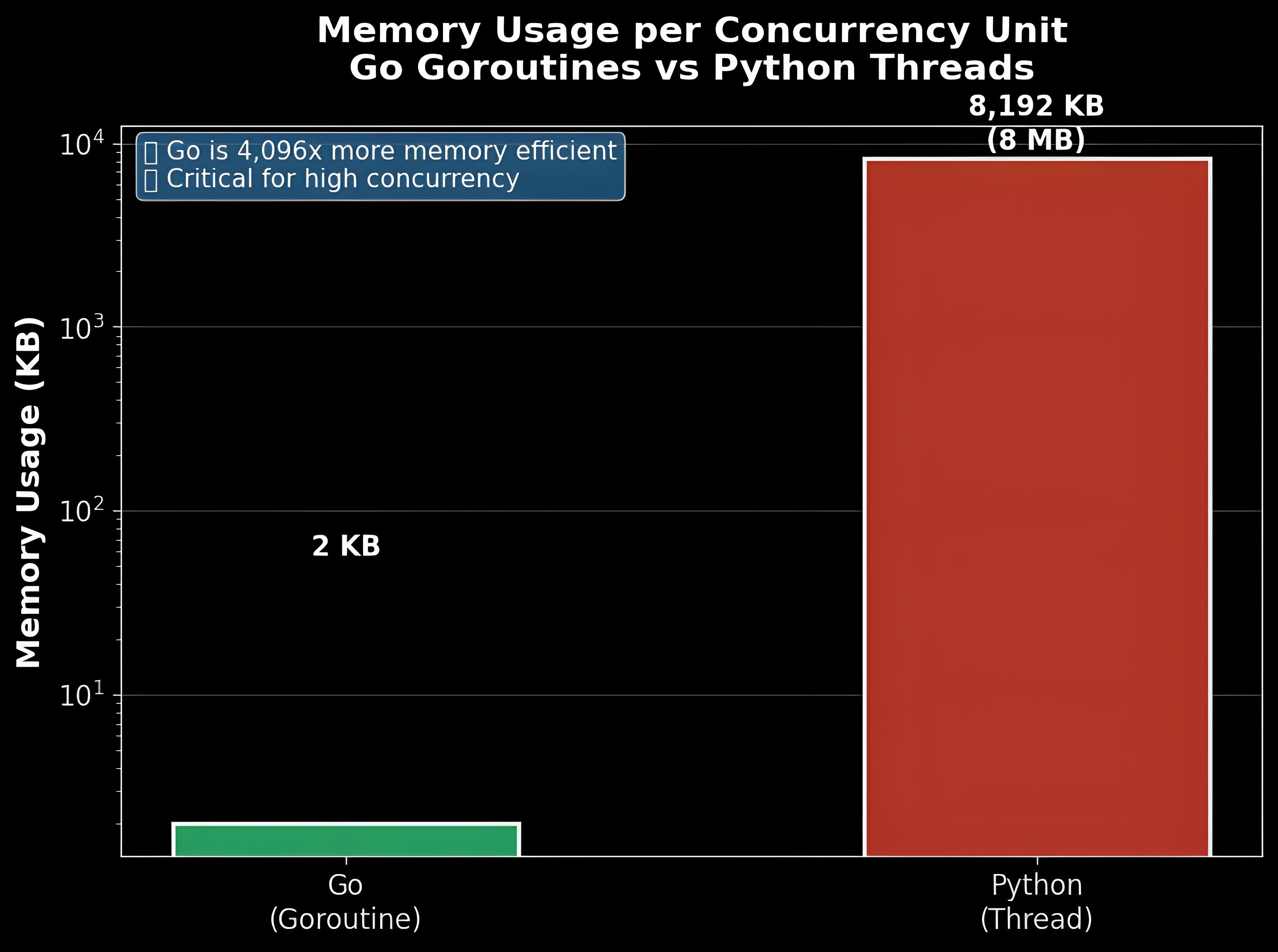
Memory Efficiency:
- Go goroutines: Start with just 2KB of stack space and grow dynamically
- Python threads: Require 8MB+ of memory per thread by default
- Impact: OS threads are relatively heavy in terms of memory usage. Each thread requires its own stack space (usually several KBs to MBs)
Concurrency Model:
- Go: Goroutines: Lightweight concurrency without a GIL - can spawn millions of goroutines
- Python: GIL prevents true multi-threading, forcing multiprocessing overhead
- Result: when it comes to handling the heat of high-concurrency workloads or CPU-intensive tasks, Python tends to wilt under pressure. Enter Go, the cool, efficient chef in the kitchen. It's fast, lean, and built to handle tough, high-demand jobs without breaking a sweat
Performance Advantages:
- Compilation: As a compiled language, Go translates straight into machine-readable code before execution. This approach leads to quicker operational speeds compared to interpreted languages like Python
- Scalability: Golang has also found a lot of application and acceptance in cloud computing or cluster computing due to its built-in support for concurrency
- Resource efficiency: Go excels in concurrency, high performance, and is well-suited for large-scale systems that require optimization in speed and resources
Flowent's approach:
- Single-process goroutines with efficient PostgreSQL state management
- Minimal memory overhead per connection
- Direct processing without inter-service communication
3. LLM-First Understanding
Traditional NLP systems require extensive preprocessing, intent classification models, and entity extraction pipelines—all CPU and memory intensive. Flowent bypasses this complexity by delegating understanding to LLMs.
Processing Comparison:
- Traditional NLP platforms: Local NLU models, intent classifiers, entity extractors, custom action servers
- Graph-based frameworks: Complex state graphs with multiple LLM calls, node-to-node state management overhead
- Flowent: Direct LLM integration with streamlined flow execution
Benefits:
- Simplified processing – no local ML model inference
- Reduced memory footprint – no model weights to load
- Better comprehension – semantic understanding vs keyword matching
- Lower latency – single LLM call vs multi-step processing
Cost Analysis: The True Financial Impact
To understand the economic impact, let's model all three architectures for enterprise deployment. For clarity, "Traditional platforms" refers to frameworks like Rasa Enterprise, while "Graph-based" refers to systems like LangGraph.
Traditional Rasa Enterprise Architecture for 20k Users
Infrastructure Requirements:
Traditional Rasa Enterprise deployments require multiple specialized components:
- Rasa Core instances: Multiple high-memory instances to handle NLU processing and dialogue management
- Rasa Action servers: Dedicated instances for custom business logic execution
- Redis cluster: For session management and caching across instances
- PostgreSQL: Database for conversation history and training data
- Load balancer and networking: Complex routing between services
Traditional Rasa Challenges:
- Complex multi-service architecture requiring extensive orchestration
- High memory requirements for local NLU models
LangGraph Architecture for 20k Users
Infrastructure Requirements:
LangGraph deployments involve several resource-intensive components:
- LangGraph API servers: Multiple instances to handle graph execution and state management
- State checkpoint storage: Redis or similar for managing complex conversation graphs
- Vector database: Memory-intensive storage for embeddings and semantic search
- PostgreSQL: Core database for persistent storage
- Load balancer and networking: Service mesh for inter-component communication
LangGraph Challenges:
- Graph state checkpointing creates significant memory overhead
- Complex node-to-node transitions require additional processing power
- Vector database maintenance adds infrastructure complexity
Flowent Architecture for 20k Users
Infrastructure Requirements:
- Flowent VPS: Simple, lightweight application servers
- PostgreSQL: Efficient state management through database
- Load balancer: Basic traffic distribution (for resilient setups)
Flowent Total:
- Dramatically simplified architecture with minimal components
- Vertical scaling to millions of users without architectural complexity
- Minimal DevOps overhead – manageable by one mid-level engineer without specialized expertise
The Financial Impact
vs Traditional Enterprise Platforms:
- Eliminate complex multi-service architectures
- Reduce infrastructure management overhead
- Result: Huge cost reduction in total ownership
Resource Efficiency Deep Dive
Memory Efficiency Comparison
| System | Memory Profile |
|---|---|
| Traditional intent-based | High memory for local NLU models, session caches |
| Graph-based | Very high memory for state checkpoints, vector databases |
| Flowent | Minimal: 12.39GB for 20k users with frequent bursts |
vCPU Utilization Analysis
| System | Resource Requirements | Constraints |
|---|---|---|
| Traditional intent-based | High CPU overhead | GIL constraints, IPC overhead |
| Graph-based | Very high CPU usage | Checkpointing + graph state overhead |
| Flowent | Minimal CPU load | Single process, goroutines, no IPC |
The Infrastructure You Don't Need
Flowent's biggest advantage is what it doesn't require:
- ❌ Redis
- ❌ Action servers
- ❌ Message queues
- ❌ Separate NLP services
- ❌ Complex state management
- ❌ Vector databases
All of these are replaced by a PostgreSQL-backed, lightweight, efficient architecture.
Migration Path for Enterprise Teams
Supported Migration Sources:
Janan Tech provides migration services from other conversational AI platforms:
- Rasa – Intent mapping and action conversion
- Dialogflow – Flow structure and entity translation
- LangGraph – State graph to declarative flow conversion
- Microsoft Bot Framework – Dialog flow restructuring
- Flowise – Node-based workflow transformation
- And others – Custom migration solutions for various platforms
Technical Migration Steps:
- Assessment: Map intents to Flowent flows
- Parallel deployment for validation
- Gradual rollout by conversation type
- A/B performance testing
- Full cutover with rollback option
Timeline: 1–4 months (vs. 6–12 months typical)
The Strategic Decision Framework
Technical Benefits
- Simplified architecture
- Vertical scaling to millions of users on single servers
- Minimal infrastructure management
- Easy cloud/on-prem portability
Financial Benefits
- Infrastructure cost savings
- Simplified procurement
- Reduced operational costs – eliminates need for senior DevOps specialists
Risk Mitigation
- Moderate migration complexity
- Proven in production
- Fast disaster recovery
The Bottom Line
20,000 concurrent users with frequent message bursts on one server isn't a benchmark—it's a paradigm shift.
Flowent proves that smart architecture can break the scale-cost tradeoff. Whether in the cloud or on dedicated infrastructure, Flowent outperforms and undercuts traditional platforms by a wide margin. For normal traffic patterns, the same infrastructure can efficiently serve millions of concurrent chat sessions.
Want hands-on performance validation? Schedule a technical deep-dive for for more information.